With the latest developments and improvements in the field of deep learning and artificial intelligence, many exacting tasks of Natural Language Processing are becoming facile to implement and execute. Text Generation is one such task which can be be architectured using deep learning models, particularly Recurrent Neural Networks. An example of text generation is the recently released Harry Potter chapter which was generated by artificial intelligence.
Text Generation is a type of Language Modelling problem. Language Modelling is the core problem for a number of of natural language processing tasks such as speech to text, conversational system, and text summarization. A trained language model learns the likelihood of occurrence of a word based on the previous sequence of words used in the text. Language models can be operated at character level, n-gram level, sentence level or even paragraph level.
In this post, I will explain how to create a language model for generating natural language text by implement and training state-of-the-art Recurrent Neural Network. I will use python programming language for this purpose. The objective of this model is to generate new text, given that some input text is present. Lets start building the architecture.
First, import the required libraries
from keras.preprocessing.sequence import pad_sequences from keras.layers import Embedding, LSTM, Dense from keras.preprocessing.text import Tokenizer from keras.callbacks import EarlyStopping from keras.models import Sequential import keras.utils as ku import numpy as np
Lets use a popular nursery rhyme — “Cat and Her Kittens” as our corpus. A corpus is defined as the collection of text documents.
data = """The cat and her kittens They put on their mittens, To eat a Christmas pie. The poor little kittens They lost their mittens, And then they began to cry. O mother dear, we sadly fear We cannot go to-day, For we have lost our mittens." "If it be so, ye shall not go, For ye are naughty kittens."""
There will be three main parts of the code: dataset preparation, model training, and generating prediction. The boiler plate code of this architecture is following:
def dataset_preparation():
pass
def create_model():
pass
def generate_text():
pass
In dataset preparation step, we will first perform Tokenization. Tokenization is a process of extracting tokens (terms / words) from a corpus. Python’s library Keras has inbuilt model for tokenization which can be used to obtain the tokens and their index in the corpus.
tokenizer = Tokenizer()
def dataset_preparation(data):
corpus = data.lower().split("\n")
tokenizer.fit_on_texts(corpus)
total_words = len(tokenizer.word_index) + 1
Next, we need to convert the corpus into a flat dataset of sentence sequences.
input_sequences = []
for line in corpus:
token_list = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(token_list)):
n_gram_sequence = token_list[:i+1]
input_sequences.append(n_gram_sequence)
Now that we have generated a data-set which contains sequence of tokens, it is possible that different sequences have different lengths. Before starting training the model, we need to pad the sequences and make their lengths equal. We can use pad_sequence function of Kears for this purpose.
max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences,
maxlen=max_sequence_len, padding='pre'))
To input this data into a learning model, we need to create predictors and label. We will create N-grams sequence as predictors and the next word of the N-gram as label. For example:
""" Sentence: "they are learning data science" PREDICTORS | LABEL they | are they are | learning they are learning | data they are learning data | science """
Lets write the code for the same
predictors, label = input_sequences[:,:-1],input_sequences[:,-1]
label = ku.to_categorical(label, num_classes=total_words)
Perfect, now we can obtain the input vector X and the label vector Y which can be used for the training purposes. Recent research experiments have shown that recurrent neural networks have shown a good performance in sequence to sequence learning and text data applications. Lets look at them in brief.
Recurrent Neural Networks
Unlike Feed-forward neural networks in which activation outputs are propagated only in one direction, the activation outputs from neurons propagate in both directions (from inputs to outputs and from outputs to inputs) in Recurrent Neural Networks. This creates loops in the neural network architecture which acts as a ‘memory state’ of the neurons. This state allows the neurons an ability to remember what have been learned so far.
The memory state in RNNs gives an advantage over traditional neural networks but a problem called Vanishing Gradient is associated with them. In this problem, while learning with a large number of layers, it becomes really hard for the network to learn and tune the parameters of the earlier layers. To address this problem, A new type of RNNs called LSTMs (Long Short Term Memory) Models have been developed.
LSTMs have an additional state called ‘cell state’ through which the network makes adjustments in the information flow. The advantage of this state is that the model can remember or forget the leanings more selectively. To learn more about LSTMs, here is a great post. Lets architecture a LSTM model in our code. I have added total three layers in the model.
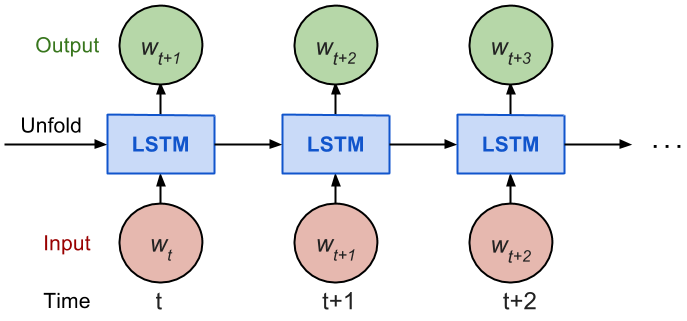
1. Input Layer : Takes the sequence of words as input 2. LSTM Layer : Computes the output using LSTM units. I have added 100 units in the layer, but this number can be fine tuned later. 3. Dropout Layer : A regularisation layer which randomly turns-off the activations of some neurons in the LSTM layer. It helps in preventing over fitting. 4. Output Layer : Computes the probability of the best possible next word as output
def create_model(predictors, label, max_sequence_len, total_words):
input_len = max_sequence_len - 1
model = Sequential()
model.add(Embedding(total_words, 10, input_length=input_len))
model.add(LSTM(150))
model.add(Dropout(0.1))
model.add(Dense(total_words, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
model.fit(predictors, label, epochs=100, verbose=1)
Great, our model architecture is now ready and we can train it using our data. Next lets write the function to predict the next word based on the input words (or seed text). We will first tokenize the seed text, pad the sequences and pass into the trained model to get predicted word. The multiple predicted words can be appended together to get predicted sequence.
def generate_text(seed_text, next_words, max_sequence_len, model):
for j in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=
max_sequence_len-1, padding='pre')
predicted = model.predict_classes(token_list, verbose=0)
output_word = ""
for word, index in tokenizer.word_index.items():
if index == predicted:
output_word = word
break
seed_text += " " + output_word
return seed_text
Lets train our model using the Cat and Her Kitten rhyme.
X, Y, max_len, total_words = dataset_preparation(data) model = create_model(X, Y, max_len, total_words)
Model’s Output when the the above model was trained on 100 epochs.
text = generate_text("cat and", 3, msl, model)
print text
>>> "cat and her lost kittens"
text = generate_text("we naughty", 3, msl, model)
print text
>>> "we naughty lost to day"
As we can see, the model has produced the output which looks fairly fine. The results can be improved further with following points:
- Adding more data
- Adding more LSTM layers
- Fine Tuning the network
- Running it for longer epoochs
You can find the complete code of this article at this link. More Reading Links: Link1, Link2. I hope you like the article, please share your thoughts in the comments section.
Also Posted on Medium Here